Randomized Benchmarking (Part 1): A fast, robust, and scalable assessment of Clifford gates
As you can see in the cover figure, quantum computing is just at the onset of its journey. There are tons of work to do before we can move to the next stage of quantum computing, quantum supremacy. Two pivotal constraints to the realization of any useful quantum processor are decoherence and the high error rate of quantum operators, or quantum gates experimentally. It’s been suggested that the probability of error per unitary gate should be less than $10^{-2}$ (better $10^{-4}$) for the outcome to be reliable. In the scope of this text, we’ll examine one prevalent technique that helps assess the error rate, therefore quality, of quantum gates. It’s called Randomized Benchmarking.
Randomized Benchmarking
Randomized Benchmarking (RB) is the process of applying random gate sequences of varying lengths to an initial state, $|0\rangle$ normally. Gates of each sequence must sum to Indentity, which means the chosen gates collectively reserve the input state, theoretically.
The fidelity of the final measurements is obtained for each sequence length. Fidelity measures the similarity/closeness of two quantum states $\rho = |\psi_{\rho}\rangle \langle \psi_{\rho} |$ and $\sigma = |\psi_{\sigma}\rangle \langle \psi_{\sigma} |$ via the overlap of them $F(\rho,\sigma) = F(\sigma,\rho) = |\langle\psi_{\rho}|\psi_{\sigma}\rangle|^2$.
1. For each sequence length, we compare the realistic outcome with the theoretically expected one. The fidelity of them is calculated following the formula above. If the experiment is conducted multiple times for a certain sequence length, we can just average the fidelities to get the representative. 2. $1 - \text{Average fidelities}$ for different sequence lengths suggest a function that decreases as the length increases (check out the figure below). 3. Average error per gate can be calculated from some parameters of the function.
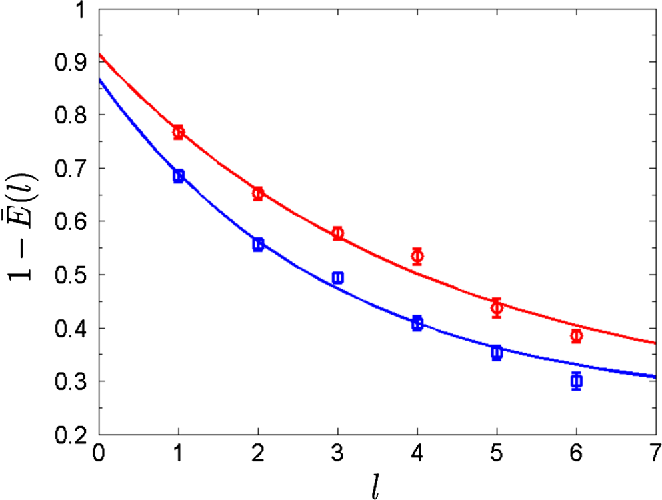
Figure of merit
Putting the procedure for implementing RB aside, we start with theoretically essential quantities in the protocol. RB was created to measure how good realistic quantum operators are in a noisy environment. The ideal transformation is denoted as $\mathcal{U}: \mathcal{U}(\rho) = U\rho U^{\dagger}$ for any unitary $U$ and density matrix $\rho$.
The presence of noise in the system can be characterized as a noise operation $\mathcal{E}$, where $\mathcal{E}$ is a completely positive, trace-preserving (CTPT) map. Note that $\mathcal{E}$ may depend on the implementation of unitary $\mathcal{U}$. However, we are going to consider $\mathcal{E}$ to be the same, or gate-independent, for all $\mathcal{U}$ for the sake of simplicity. So, it’s convenient that we can be always to represent the practically-performed operation $\mathcal{\tilde{U}} = \mathcal{E} \circ \mathcal{U}$ where $\circ$ denotes composition (i.e. apply $\mathcal{E}$ then apply $\mathcal{U}$). The average (gate) fidelity is the measure of the quality of the practical implementation $\mathcal{\tilde{U}}$ compared to its ideal counterpart $\mathcal{U}$: $$F_{avg}(\mathcal{U},\mathcal{\tilde{U}}):= \int \text{Tr}(\mathcal{U} (|\psi\rangle \langle \psi|) \mathcal{\tilde{U}} (\psi\rangle \langle \psi|)) d\psi,$$ where $d\psi$ is the uniform Haar measurement over pure quantum states. Doing some math with the integrand we get $\text{Tr}(\mathcal{U} (|\psi\rangle \langle \psi|) \mathcal{\tilde{U}} (|\psi\rangle \langle \psi|))$ $= \text{Tr}(U|\psi\rangle \langle \psi| U^{\dagger} UE|\psi\rangle \langle \psi| E^{\dagger}U^{\dagger})$ $= \text{Tr}(E|\psi\rangle \langle \psi|E^{\dagger}|\psi\rangle \langle \psi|)$ because of the communicativeness of trace and $UU^{\dagger} = I$. This explicitly explains $$F_{avg}(\mathcal{U},\mathcal{\tilde{U}}) = F_{avg}(\mathcal{E},\mathcal{I}),$$ where $\mathcal{I}$ is the identity operation. The average infidelity $r$ is defined simply as $$r(\mathcal{E}) := 1 - F_{avg}(\mathcal{E},\mathcal{I})$$ Next we define a new quantity, $f(\mathcal{E})$ as the “depolarizing parameter” corresponding to the quantum channel $\mathcal{E}$. RB can be used to estimate this quantity. $$f(\mathcal{E}) := \frac{dF_{avg}(\mathcal{E},\mathcal{I})-1}{d-1},$$ where d is the dimension of the state space, $d = \text{dim}(\mathscr{H})$, normally $2^n$, where n is the number of qubits in the system.
Use of Clifford Gates
We’re gonna perform RB to assess the elements taken from the Clifford group. It’s a group of unitary gates constructed by all possible combinations of generating operators: $\mathbf{CNOT}, \mathbf{H}, \mathbf{S}$ ($\pi/4$ phase gate). Some of Clifford gates are {$\mathbf{X},\mathbf{Y},\mathbf{Z},\mathbf{H},\mathbf{S},\mathbf{S^{\dagger}},\mathbf{CX},\mathbf{CZ},\mathbf{SWAP}$}. Theoretically, these gates assure that the final measurement yields a deterministic outcome in the absence of error. But there are many more gates that also satisfy such a condition. So, why Clifford group?
There are several compelling reasons supporting the use of Clifford operators over arbitrary unitaries in the implementation of RB: • The Clifford group is finite in number of elements, so it’s easy to calibrate them for small qubit number $n$. Moreover, each Clifford gate can be constructed using a finite number of generating gates that can be calibrated. Unitary gates, in general, don’t have such a set of generating gates and therefore cannot be constructed with a set of gates under proper calibration. • It’s practice that the Clifford gates are the basis of many quantum error-correction protocols. Quantifying their gate fidelity is essential in determining the possible error correction scheme for a given architecture. • At the end of the gate sequence may require inverting an enormous product of preceeding gates. For arbitrary unitaries, the inversion algorithm’s complexity scales exponentially with $n$, which is impossible with our classical computing technology even for not-really-large $n$. On the other hand, the inversion algorithm for Clifford operators only require time of order $O(n^3)$, so tractable even for very large $n$. • In contrast to the infinite number of possible unitary sequences of fixed length, the number of possible Clifford sequences of fixed length is finite. It conveniently replaces all integrals over unitaries with sums over Clifford operators. It also allows the analysis of the degree to which the sum of a small number of sequence fidelities approximates the sum over all sequence fidelities (in comparison to analyzing the convergence of a finite sum of sequences to the integral over all unitary sequences)
The next parts are about constructing the protocol and deriving some necessary equations in the model.